pytorch
pytorch和神经网络学习笔记。
安装
例如:
1 | pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 |
如果网络老是中断,可以先从.whl文件安装torch
1 | pip install D:\Users\xxx\Downloads\torch-2.1.0+cu118-cp311-cp311-win_amd64.whl |
然后在执行第一个命令,安装torchvision torchaudio。
神经网络概述
DNN (Deep Neural Network)、RNN (Recurrent Neural Network)、CNN (Convolutional Neural Network) 和图神经网络 (Graph Neural Network) 都是深度学习领域中常见的神经网络架构,它们各自适用于不同类型的数据和任务。以下是对每种神经网络的简要介绍:
- 深度神经网络 (DNN):
- DNN是一种标准的前馈神经网络,它由输入层、多个隐藏层和输出层组成。
- DNN广泛用于图像分类、文本分类、回归、语音识别等任务。
- 深层结构允许DNN从数据中自动学习高级特征表示,从而提高性能。
- 循环神经网络 (RNN):
- RNN是一种递归神经网络,具有循环连接,能够处理序列数据。
- RNN具有内部状态,允许它记忆先前的信息并将其传递到后续时间步。
- RNN常用于自然语言处理 (NLP)、时间序列分析、语音识别等需要考虑上下文的任务。
- 卷积神经网络 (CNN):
- CNN是专门设计用于图像处理的神经网络。
- 它使用卷积层来检测图像中的特征,如边缘、纹理和形状。
- CNN在计算机视觉任务中表现出色,如图像分类、目标检测和图像分割。
- 图神经网络 (Graph Neural Network, GNN):
- GNN是为处理图数据而设计的神经网络,如社交网络、知识图谱和分子结构。
- GNN能够在节点和边上执行信息传递,考虑了图数据的拓扑结构。
- GNN用于图分类、节点分类、链接预测等任务,并在推荐系统和生物信息学中也有广泛应用。
基本成员
Tensor
1 | .cuda() |
Module(Model)
1 | .cuda() |
optim
SGD
1 | #1. 创建模型 |
基本方法
randn
1 | torch.randn(5, 3, 224, 224) -> tensor |
预设模型
torchvision.models
1 | resnet18() |
常用模型
LSHModel
局部哈希敏感模型
1 | import torch |
Profiler
参考文档:PyTorch Profiler — PyTorch Tutorials 2.1.0+cu121 documentation
基础知识
pytorch profiler通过上下文管理器开启,可以接收很多设置参数,比如:
activities- 分析活动的列表ProfilerActivity.CPU- Pytorch操作符,TorchScript函数,和用户定义的代码标签(见下面的record_function)ProfileActivity.CUDA- 设备上的CUDA内核
record_shapes- 是否记录每次操作的输入的形状profile_memory- 是否报告模型张量消耗的内存量use_cuda- 是否测量CUDA内核的执行时间
注意:当使用CUDA时,profiler还会展示主机上发生的运行时CUDA事件。
导入库
1 | import torch |
实例化一个简单的Resnet模型
1 | model = models.resnet18() # 在CPU上 |
使用profiler分析执行时间
only CPU
1 | with profile(activities=[ProfilerActivity.CPU], record_shapes=True) as prof: |
从上面我们可以看到,我们可以通过record_function上下文管理器,使用用户提供的名字来标记任意代码范围(在上面的例子中,model_inference被用作标签)。
在执行被上下文管理器包装的代码范围期间,profiler允许检查哪些操作符被调用了。如果多个profiler范围同时处于活动(active)状态(例如,在并行的pytorch线程中),则每个profiling上下文管理器仅跟踪其相应范围的运算。
Profiler还会自动评测使用torch.jit_fork启动的异步任务,以及(在向后传递的情况下)用backward()调用启动的向后传递运算符。
下面打印以上执行的数据:
1 | print(prof.key_averages()) |
或
1 | print(prof.key_averages().table(sort_by="cpu_time_total", row_limit=10)) |
输出如下:
1 | --------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ |
可以看到,aten::mkldnn_convolution函数的Self CPU最高。
其中 Self CPU 和 CPU 的区别在于,前者减去了子操作的执行时间,后者保留了子操作的执行时间。
可以在table()中使用sort_by="self_cpu_time_total“,根据 self cpu 时间对输出进行排序。
为了获得更细粒度的输出,包含操作输入的形状,可以使用group_by_input_shape(要求运行profiler时开启record_shapes=True):
1 | print(prof.key_averages(group_by_input_shape=True)).table(sort_by="self_cpu_time_total", row_limit=10) |
输出如下(省略了一些列):
1 | --------------------------------- ------------ ------------ ... ---------------------------------------------------------- |
with GPU
profiler也可以用来分析在GPU上执行的模型的性能:
1 | model = models.resnet18().cuda() |
输出如下(省略了一些行):
1 | ---------------------------- ---------- --------- ---------- ----------- ---------- ------------ ---------- |
注:第一次使用cuda profiling会引入额外的开销,导致运行时间较长,之后就相对正常了:
1 | Self CPU time total: 192.059ms |
使用profiler分析内存开销
profiler能够统计模型运行过程中tensor使用获释放的内存数量,profile_memory=True:
1 | import torch |
使用跟踪功能
通过export_chrome_trace,profiler的分析结果能够输出为一个.json(跟踪)文件。
1 | model = models.resnet18().cuda() |
在浏览中访问chrome//tracing或edge://tracing,加载生成的trace.json文件,界面如下:
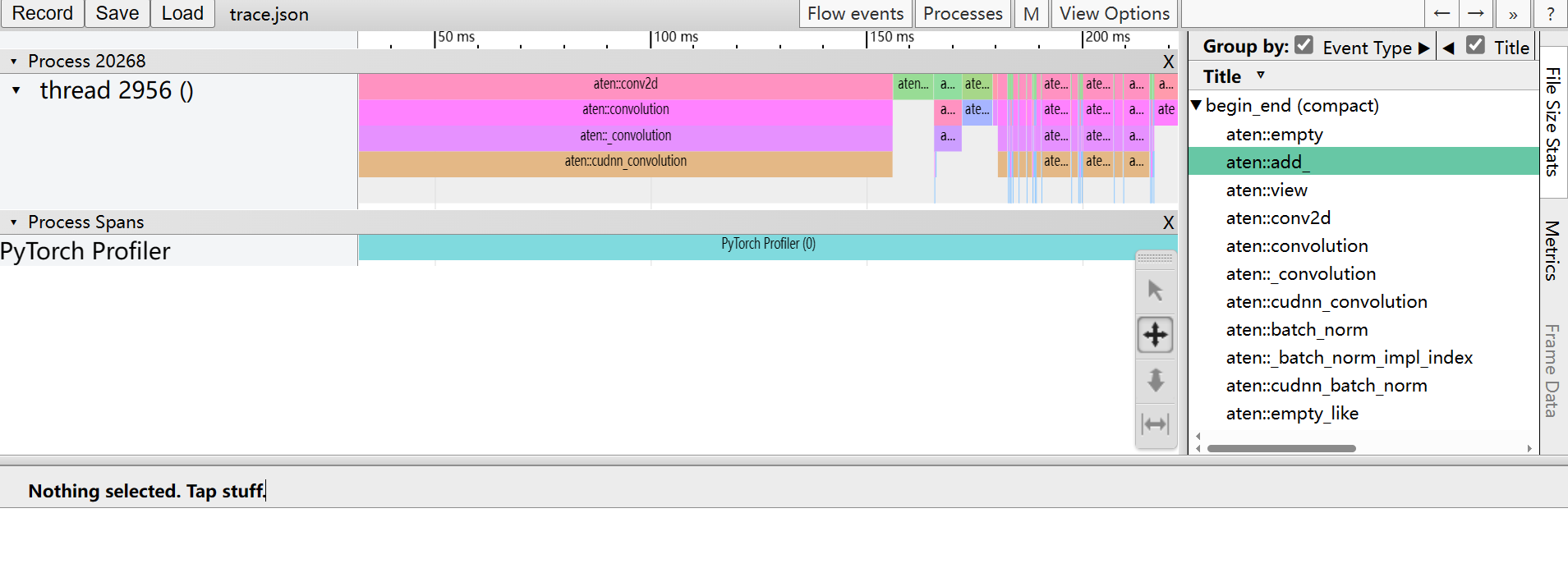
检查栈跟踪
Profiler能够被用来分析Python和TorchScript的栈跟踪:
1 | with profile( |
【测试失败!】(未输出堆栈信息)
将数据可视化为火焰图
执行时间(self_cpu_time_total和self_cuda_time_total)和栈跟踪能够被可视化为一个火焰图。
首先使用export_stacks导出原始数据(需要with_stack=True)
1 | prof.export_stacks("./profiler_stacks.txt", "self_cuda_time_total") |
【测试失败!】(生成的文件为空)
推荐使用 Flamegraph tool 生成一个可交互的.svg文件
1 | git clone https://github.com/brendangregg/FlameGraph |
使用profiler分析长时间运行的工作
Pytorch profiler提供一个额外的API用于处理长时间运行的工作(如训练循环)。如果跟踪所有的执行,会很慢,生成的跟踪文件也会很大。为了避免这样,可以使用以下可选参数:
schedule- 指定一个以整数参数(步长)为输入的函数,如torch.profiler.schedule帮助函数,生成一个shcedule。on-trace-ready- 指定一个以profiler引用为输入的回调函数,每次当新跟踪准备好时,去调用该函数
首先考虑以下示例:
1 | from torch.profiler import schedule |
下面是更完整的示例:
1 | def trace_handler(p): |